 https://www.getfulltextresearch.com/wp-content/uploads/2026/07/iStock-2267168890-e1784211508516.jpg
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2026-07-16 15:53:172026-07-17 15:02:36Why Publishers Should Join GetFTR
https://www.getfulltextresearch.com/wp-content/uploads/2026/07/iStock-2267168890-e1784211508516.jpg
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2026-07-16 15:53:172026-07-17 15:02:36Why Publishers Should Join GetFTR
GetFTR: dataflows and user privacy
Data privacy is a topic that, rightly so, is top-of-mind for many researchers and organisations that are active in the space of scholarly communications. GetFTR is committed to safeguarding the privacy of its users, and we take this principle to heart as we continue to deliver on our mission to create streamlined access to high-quality publications for global researchers, no matter their location.
We have previously written about how GetFTR preserves user privacy as we expanded access options in a blog post towards the end of last year.
In today’s post, two of GetFTR’s leadership team – Dianne Benham and Hylke Koers – discuss the topic further and go into more detail on the inner workings of GetFTR. We’ve decided to talk not only about general principles but also to include a fair bit of technical detail. We believe that it is important to be clear and transparent about what kind of data is needed for the GetFTR service to work, and how that data flows between the central GetFTR system, services that integrate with GetFTR, and publishers.
####
Recap: What is GetFTR?
GetFTR is a service that streamlines access to trusted, published research from discovery tools and collaboration networks, a mission that we believe is more important and urgent than ever. With GetFTR, users from such services can quickly tell which published content is accessible to them (which could be because it is Open Access, or because their institution has subscribed to the content), and follow links to rapidly access published research on participating publisher or aggregator websites. This reduces unnecessary steps, paywalls and frustration.
For an overview of GetFTR and what problems it solves, we recommend watching the video “An introduction to GetFTR” .
At its core, GetFTR is a service that answers the question “Can someone from this institution access these publications?” In more technical terms, such a question is referred to as an entitlement check, and GetFTR offers the capability to perform entitlement checks for a list of publications (identified by DOIs) and a specific institution. This enables GetFTR integrators, such as discovery tools and collaboration networks, to signal to their users which content they are entitled to access.
GetFTR only requires article identifiers (DOIs) and information about the user’s institutional affiliation for entitlement checks. It does not require or capture any other information about the user.
The mechanics of how these entitlement requests are handled is described in the illustration before:
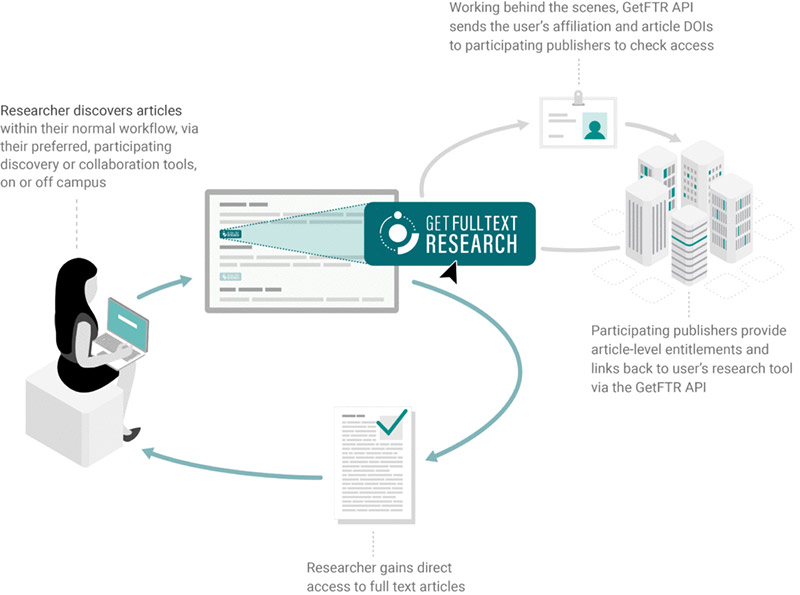
Step 1: Integrator Entitlement Requests
The process starts when a researcher begins their discovery journey on a service that integrates with GetFTR, and that service wants to display their entitlement to the user. To achieve this, the integrator service queries the GetFTR system with a combination of DOI’s and the user’s affiliation.
The user’s affiliation can be encoded by a number of organisational identifiers which are collected by the integrator and passed to GetFTR (and, subsequently, on to the publisher – see below) for entitlement checking purposes. One such standard identifier is the SAML EntityID corresponding to a user’s institution; this information will have been provided to the integrator directly by the user, for example in their profile (see figure below).
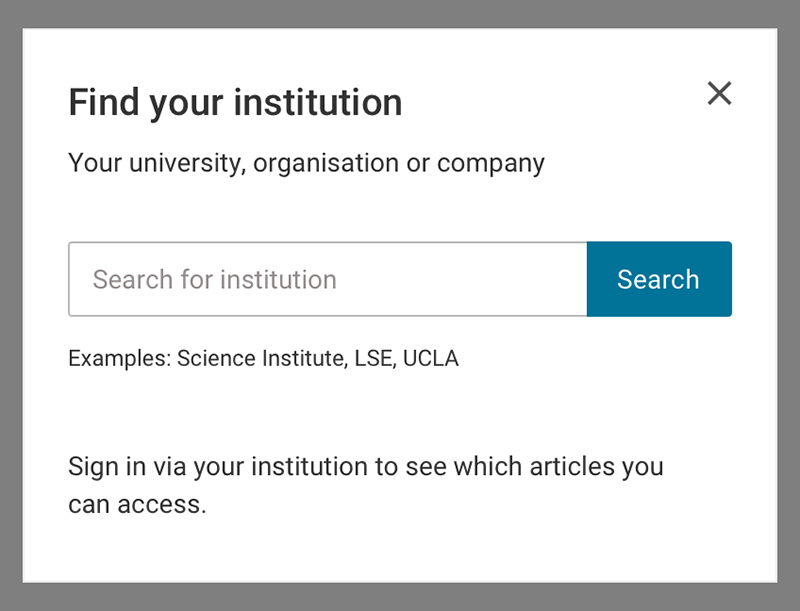
Institution selection – illustration of how a user may enter their affiliation on the website of a service integrating with GetFTR. This enables the integrator to query the GetFTR system to see if the user is entitled, via their institution, to a specific piece of content
Another commonly used identifier is the user’s IP address. Support for IP-based authentication was added to GetFTR after the initial launch upon request from users and in consultation with pilot participants and the GetFTR advisory board.
This means that integrators can also share user’s IP addresses with GetFTR, although this is optional. Those that choose to share user’s IP addresses with GetFTR and participating publishers, have to notify users via their privacy policy ahead of doing so. GetFTR and publishers who receive IP address information from GetFTR are only allowed to use this for the purposes of checking entitlements.
Note: Most Discovery Services implement deferred authentication, which means the user authenticates after they have clicked on a GetFTR link to access content on a publisher or aggregator site (unless they are already authenticated). Some Discovery Services chose to handle authentication themselves. Once the user is authenticated, GetFTR links provide one-click access to content across all participating publisher and aggregator platforms.
Step 2: GetFTR Processing
When GetFTR receives an entitlement request, it checks the entitlement status with the relevant publisher in real-time. To enable this, GetFTR uses Crossref metadata to determine which publisher is associated with a particular piece of content (identified by DOI), and then routes the entitlement request to the correct publisher. Only the relevant publisher will receive the entitlement request; this data is not shared with other publishers or organisations.
Step 3: Publisher Entitlement Responses
For every document, the publisher returns a corresponding “entitlement resource” to GetFTR, which is a piece of information that establishes the level of entitlement (e.g. yes, no); access type (e.g. open, free, paid); document type (e.g. version of record or alternative version); content type (e.g. html, pdf) and a link to the actual resource if appropriate. GetFTR, in turn, sends this entitlement resource on to the integrator where it can be used to signal to the user if they will have access to the content.
Step 4: Integrator display entitlement
Having received the entitlement resource, the integrator now knows which content items the user has access to, and uses that information to display the appropriate GetFTR indicators. In addition, if the user is entitled to access the content, the publisher sends a ‘smart link’ that allows the user to bypass repetitive authentication steps.
What does GetFTR not do?
GetFTR does not store information about its users, which links the user clicks on the integrator’s site, or which articles they view on a publisher’s platform
GetFTR also does not control or mediate access in any way. Once a user clicks on a link from an integrator, they are directed to the publisher’s platform where they still need to be authenticated and authorized. For users using SAML based-access (federated access), GetFTR does streamline the access user journey by providing ‘smart links’ (which are in essence so-called WAYFless URLs) to the integrator. Such a smart link contains the user’s institutional affiliation, but no other user data, thereby effectively passing that information along from an integrator service to a publisher. The publisher, in turn, can use this information to direct the user to their institution’s login page or directly to the content if they are already authenticated.
As always we welcome further discussion should you have thoughts, comments or want to know more information. For this please contact Dianne Dianne Benham (GetFTR Product) Dianne@getfulltextresearch.com
https://www.getfulltextresearch.com/wp-content/uploads/2026/07/iStock-2267168890-e1784211508516.jpg
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2026-07-16 15:53:172026-07-17 15:02:36Why Publishers Should Join GetFTR https://www.getfulltextresearch.com/wp-content/uploads/2026/06/iStock-1262919347-e1782166892595.jpg
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2026-06-22 23:40:042026-06-23 12:02:45If Content Can Be Read Anywhere, How Do Publishers Measure Its Impact?
https://www.getfulltextresearch.com/wp-content/uploads/2026/06/iStock-1262919347-e1782166892595.jpg
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2026-06-22 23:40:042026-06-23 12:02:45If Content Can Be Read Anywhere, How Do Publishers Measure Its Impact? https://www.getfulltextresearch.com/wp-content/uploads/2026/06/new-partners-PNAS.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2026-06-16 12:00:392026-06-16 12:18:17Press Release: PNAS Partners with GetFTR to Improve Discovery and Access to Trusted Research
https://www.getfulltextresearch.com/wp-content/uploads/2026/06/new-partners-PNAS.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2026-06-16 12:00:392026-06-16 12:18:17Press Release: PNAS Partners with GetFTR to Improve Discovery and Access to Trusted Research https://www.getfulltextresearch.com/wp-content/uploads/2026/05/new-partners-EBSCO.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2026-05-11 14:25:542026-06-16 12:01:41Press Release: EBSCO Information Services and GetFTR Partner to Streamline Access to Full Text
https://www.getfulltextresearch.com/wp-content/uploads/2026/05/new-partners-EBSCO.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2026-05-11 14:25:542026-06-16 12:01:41Press Release: EBSCO Information Services and GetFTR Partner to Streamline Access to Full Text https://www.getfulltextresearch.com/wp-content/uploads/2026/04/new-partners-ASHA-2.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2026-04-30 15:30:432026-04-30 15:31:22Press Release: ASHA Journals Joins GetFTR
https://www.getfulltextresearch.com/wp-content/uploads/2026/04/new-partners-ASHA-2.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2026-04-30 15:30:432026-04-30 15:31:22Press Release: ASHA Journals Joins GetFTR https://www.getfulltextresearch.com/wp-content/uploads/2026/04/new-partners-CoB.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2026-04-20 14:05:052026-04-21 17:15:40Press Release: The Company of Biologists Joins GetFTR
https://www.getfulltextresearch.com/wp-content/uploads/2026/04/new-partners-CoB.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2026-04-20 14:05:052026-04-21 17:15:40Press Release: The Company of Biologists Joins GetFTR https://www.getfulltextresearch.com/wp-content/uploads/2026/03/TF-Case-Study-e1773925174342.jpg
534
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2026-03-19 13:24:052026-04-21 17:16:32How Taylor & Francis and GetFTR Enhance Research Integrity and Discovery
https://www.getfulltextresearch.com/wp-content/uploads/2026/03/TF-Case-Study-e1773925174342.jpg
534
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2026-03-19 13:24:052026-04-21 17:16:32How Taylor & Francis and GetFTR Enhance Research Integrity and Discovery https://www.getfulltextresearch.com/wp-content/uploads/2026/03/AI-Brainstorming-scaled-e1773056833764.jpg
533
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2026-03-09 14:51:332026-04-21 17:17:05How GetFTR Connects AI Sources to Trusted Content
https://www.getfulltextresearch.com/wp-content/uploads/2026/03/AI-Brainstorming-scaled-e1773056833764.jpg
533
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2026-03-09 14:51:332026-04-21 17:17:05How GetFTR Connects AI Sources to Trusted Content https://www.getfulltextresearch.com/wp-content/uploads/2026/02/new-partners-feb-800-x-500-px-jan26.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2026-02-11 15:16:482026-04-21 17:17:27GetFTR Announces New Partnerships
https://www.getfulltextresearch.com/wp-content/uploads/2026/02/new-partners-feb-800-x-500-px-jan26.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2026-02-11 15:16:482026-04-21 17:17:27GetFTR Announces New Partnerships https://www.getfulltextresearch.com/wp-content/uploads/2026/01/Screenshot-2026-01-28-at-11.48.05-e1769600963602.png
537
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2026-01-28 14:16:392026-04-21 17:18:03IOP Publishing and GetFTR – Strengthening Discovery & Integrity
https://www.getfulltextresearch.com/wp-content/uploads/2026/01/Screenshot-2026-01-28-at-11.48.05-e1769600963602.png
537
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2026-01-28 14:16:392026-04-21 17:18:03IOP Publishing and GetFTR – Strengthening Discovery & Integrity https://www.getfulltextresearch.com/wp-content/uploads/2026/01/Press-Release-tile-800-x-500-px-jan26.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2026-01-22 11:57:152026-04-21 17:18:28GetFTR Enables AI Tools to Check Access Rights for Academic Content
https://www.getfulltextresearch.com/wp-content/uploads/2026/01/Press-Release-tile-800-x-500-px-jan26.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2026-01-22 11:57:152026-04-21 17:18:28GetFTR Enables AI Tools to Check Access Rights for Academic Content https://www.getfulltextresearch.com/wp-content/uploads/2025/12/product-update-BE.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-12-10 14:52:432025-12-10 15:10:55Product Update: Enhancements to the GetFTR Browser Extension
https://www.getfulltextresearch.com/wp-content/uploads/2025/12/product-update-BE.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-12-10 14:52:432025-12-10 15:10:55Product Update: Enhancements to the GetFTR Browser Extension https://www.getfulltextresearch.com/wp-content/uploads/2025/12/Part-Three-GetFTR-Insights-.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-12-07 19:18:302026-04-21 17:19:13Insights Part Three: Collaboration and Innovation: How Publishers Prove Shared Infrastructure Works
https://www.getfulltextresearch.com/wp-content/uploads/2025/12/Part-Three-GetFTR-Insights-.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-12-07 19:18:302026-04-21 17:19:13Insights Part Three: Collaboration and Innovation: How Publishers Prove Shared Infrastructure Works https://www.getfulltextresearch.com/wp-content/uploads/2025/11/zanitech-2.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-11-26 16:39:342026-04-21 17:19:40How Zenitech Helped GetFTR Scale, Innovate, and Strengthen Research Integrity
https://www.getfulltextresearch.com/wp-content/uploads/2025/11/zanitech-2.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-11-26 16:39:342026-04-21 17:19:40How Zenitech Helped GetFTR Scale, Innovate, and Strengthen Research Integrity https://www.getfulltextresearch.com/wp-content/uploads/2025/11/Part-Two-GetFTR-Insights-.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-11-17 15:36:342026-04-21 17:20:03Insights from the GetFTR Founders, Part Two: Integrity, Trust & how GetFTR Strengthens the Scholarly Record
https://www.getfulltextresearch.com/wp-content/uploads/2025/11/Part-Two-GetFTR-Insights-.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-11-17 15:36:342026-04-21 17:20:03Insights from the GetFTR Founders, Part Two: Integrity, Trust & how GetFTR Strengthens the Scholarly Record https://www.getfulltextresearch.com/wp-content/uploads/2025/10/Part-One-GetFTR-Insights-2.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-10-24 11:58:512026-04-21 17:20:25Insights from the GetFTR Founders: Part One: safeguarding visibility and integrity of content
https://www.getfulltextresearch.com/wp-content/uploads/2025/10/Part-One-GetFTR-Insights-2.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-10-24 11:58:512026-04-21 17:20:25Insights from the GetFTR Founders: Part One: safeguarding visibility and integrity of content https://www.getfulltextresearch.com/wp-content/uploads/2025/10/WoS-Announcement.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-10-13 13:26:392026-04-21 17:20:56GetFTR and the Web of Science Partner to Streamline Research Discovery and Access
https://www.getfulltextresearch.com/wp-content/uploads/2025/10/WoS-Announcement.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-10-13 13:26:392026-04-21 17:20:56GetFTR and the Web of Science Partner to Streamline Research Discovery and Access https://www.getfulltextresearch.com/wp-content/uploads/2025/09/business-concept-glass-world-laptop-scaled.jpg
1707
2560
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-09-18 13:45:392026-06-16 16:40:32CABI and GetFTR – Enhancing Access and Impact Across the Global Research Community
https://www.getfulltextresearch.com/wp-content/uploads/2025/09/business-concept-glass-world-laptop-scaled.jpg
1707
2560
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-09-18 13:45:392026-06-16 16:40:32CABI and GetFTR – Enhancing Access and Impact Across the Global Research Community https://www.getfulltextresearch.com/wp-content/uploads/2025/09/New-Integrations.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-09-15 11:13:102025-09-15 16:01:25GetFTR Improves Research Access with New Discovery Integrations
https://www.getfulltextresearch.com/wp-content/uploads/2025/09/New-Integrations.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-09-15 11:13:102025-09-15 16:01:25GetFTR Improves Research Access with New Discovery Integrations https://www.getfulltextresearch.com/wp-content/uploads/2025/09/product-update.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-09-01 12:47:222025-09-01 13:44:57New features improve discovery and access to academic content
https://www.getfulltextresearch.com/wp-content/uploads/2025/09/product-update.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-09-01 12:47:222025-09-01 13:44:57New features improve discovery and access to academic content https://www.getfulltextresearch.com/wp-content/uploads/2025/07/call-center-worker-using-ai-tech-laptop-reply-customers-closeup-scaled-e1753363404302.jpg
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-07-24 14:38:092025-07-24 14:44:48AI Tools + GetFTR: Make the Research Pathway from Discovery to Access Smarter
https://www.getfulltextresearch.com/wp-content/uploads/2025/07/call-center-worker-using-ai-tech-laptop-reply-customers-closeup-scaled-e1753363404302.jpg
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-07-24 14:38:092025-07-24 14:44:48AI Tools + GetFTR: Make the Research Pathway from Discovery to Access Smarter https://www.getfulltextresearch.com/wp-content/uploads/2025/07/person-holding-frame-with-open-nature-landscape-concept-scaled-e1753200041839.jpg
508
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-07-22 15:16:512025-07-22 17:01:23GetFTR Turns Five: What We’ve Delivered – and What’s Next
https://www.getfulltextresearch.com/wp-content/uploads/2025/07/person-holding-frame-with-open-nature-landscape-concept-scaled-e1753200041839.jpg
508
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-07-22 15:16:512025-07-22 17:01:23GetFTR Turns Five: What We’ve Delivered – and What’s Next https://www.getfulltextresearch.com/wp-content/uploads/2025/07/New-Integrations-LL-and-Scite.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-07-10 14:55:122025-07-10 14:57:00New Integrations with Lean Library and Scite to Streamline Access to Research
https://www.getfulltextresearch.com/wp-content/uploads/2025/07/New-Integrations-LL-and-Scite.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-07-10 14:55:122025-07-10 14:57:00New Integrations with Lean Library and Scite to Streamline Access to Research https://www.getfulltextresearch.com/wp-content/uploads/2025/07/Press-Release-tile-800-x-500-px.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-07-04 11:41:592025-07-04 11:49:46GetFTR Update, Newsletter and Webinar Available
https://www.getfulltextresearch.com/wp-content/uploads/2025/07/Press-Release-tile-800-x-500-px.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-07-04 11:41:592025-07-04 11:49:46GetFTR Update, Newsletter and Webinar Available https://www.getfulltextresearch.com/wp-content/uploads/2025/06/Anniversary-Celebration-Post-800-x-500-px-2.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-06-26 12:50:032025-06-26 12:53:06A review and and celebration of five years of GetFTR’s cross-industry collaboration
https://www.getfulltextresearch.com/wp-content/uploads/2025/06/Anniversary-Celebration-Post-800-x-500-px-2.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-06-26 12:50:032025-06-26 12:53:06A review and and celebration of five years of GetFTR’s cross-industry collaboration https://www.getfulltextresearch.com/wp-content/uploads/2025/06/SEG-and-RSNA-RE.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-06-17 12:19:432026-04-21 17:24:11RSNA and SEG Implement Retraction and Errata Feature to Strengthen Research Integrity
https://www.getfulltextresearch.com/wp-content/uploads/2025/06/SEG-and-RSNA-RE.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-06-17 12:19:432026-04-21 17:24:11RSNA and SEG Implement Retraction and Errata Feature to Strengthen Research Integrity https://www.getfulltextresearch.com/wp-content/uploads/2023/05/samantha-borges-EeS69TTPQ18-unsplash-scaled.jpg
1707
2560
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-06-04 13:35:542025-06-04 13:38:16Five Years and Counting! A GetFTR Update Webinar
https://www.getfulltextresearch.com/wp-content/uploads/2023/05/samantha-borges-EeS69TTPQ18-unsplash-scaled.jpg
1707
2560
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-06-04 13:35:542025-06-04 13:38:16Five Years and Counting! A GetFTR Update Webinar https://www.getfulltextresearch.com/wp-content/uploads/2025/05/TF-RE-1.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-05-19 08:17:082025-05-19 15:33:45Taylor & Francis Online Displays Retraction and Errata Buttons in References
https://www.getfulltextresearch.com/wp-content/uploads/2025/05/TF-RE-1.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-05-19 08:17:082025-05-19 15:33:45Taylor & Francis Online Displays Retraction and Errata Buttons in References https://www.getfulltextresearch.com/wp-content/uploads/2025/04/library-blog-scaled-e1745921169968.jpg
533
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-04-29 11:14:032025-04-29 11:21:10Empowering Librarians: Streamlined Access for Researchers and Tools for Librarians
https://www.getfulltextresearch.com/wp-content/uploads/2025/04/library-blog-scaled-e1745921169968.jpg
533
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-04-29 11:14:032025-04-29 11:21:10Empowering Librarians: Streamlined Access for Researchers and Tools for Librarians https://www.getfulltextresearch.com/wp-content/uploads/2025/04/product-update3-2.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-04-16 18:05:152025-04-16 18:46:19New Feature: Save to Reference Managers with the GetFTR Browser Extension
https://www.getfulltextresearch.com/wp-content/uploads/2025/04/product-update3-2.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-04-16 18:05:152025-04-16 18:46:19New Feature: Save to Reference Managers with the GetFTR Browser Extension https://www.getfulltextresearch.com/wp-content/uploads/2025/03/chris-montgomery-smgTvepind4-unsplash-e1742990522430.jpg
545
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-03-26 14:58:542025-03-26 15:01:27GetFTR Joins Key Industry Webinars in April: Retractions, Streamlined Access & Syndicated Usage
https://www.getfulltextresearch.com/wp-content/uploads/2025/03/chris-montgomery-smgTvepind4-unsplash-e1742990522430.jpg
545
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-03-26 14:58:542025-03-26 15:01:27GetFTR Joins Key Industry Webinars in April: Retractions, Streamlined Access & Syndicated Usage https://www.getfulltextresearch.com/wp-content/uploads/2025/03/business-executives-writing-sticky-notes-scaled-e1741693751201.jpg
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-03-11 12:24:092025-03-11 12:26:20Insights from Researcher to Reader
https://www.getfulltextresearch.com/wp-content/uploads/2025/03/business-executives-writing-sticky-notes-scaled-e1741693751201.jpg
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-03-11 12:24:092025-03-11 12:26:20Insights from Researcher to Reader https://www.getfulltextresearch.com/wp-content/uploads/2025/03/product-update2.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-03-05 11:47:292025-03-05 11:47:34GetFTR Expands Support for Perpetual Rights and Journal Transfers
https://www.getfulltextresearch.com/wp-content/uploads/2025/03/product-update2.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-03-05 11:47:292025-03-05 11:47:34GetFTR Expands Support for Perpetual Rights and Journal Transfers https://www.getfulltextresearch.com/wp-content/uploads/2025/02/product-update-2.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-02-07 08:12:042025-02-07 08:55:06GetFTR adds Smartlinks and Retraction and Errata to Preprint Websites
https://www.getfulltextresearch.com/wp-content/uploads/2025/02/product-update-2.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-02-07 08:12:042025-02-07 08:55:06GetFTR adds Smartlinks and Retraction and Errata to Preprint Websites https://www.getfulltextresearch.com/wp-content/uploads/2025/01/new-integration-2.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-01-28 16:23:452025-01-29 10:06:32APA PsycInfo Integrates GetFTR’s Retraction and Errata Feature
https://www.getfulltextresearch.com/wp-content/uploads/2025/01/new-integration-2.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-01-28 16:23:452025-01-29 10:06:32APA PsycInfo Integrates GetFTR’s Retraction and Errata Feature https://www.getfulltextresearch.com/wp-content/uploads/2023/01/new-partner-background.jpg
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-01-09 12:04:172025-01-27 16:52:32Taylor & Francis eBooks Platform Integrates with GetFTR
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/new-partner-background.jpg
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2025-01-09 12:04:172025-01-27 16:52:32Taylor & Francis eBooks Platform Integrates with GetFTR https://www.getfulltextresearch.com/wp-content/uploads/2024/12/R2R.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-12-19 16:41:152024-12-19 16:49:33Going to Researcher to Reader? Don’t forget to sign up for our workshop!
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/new-partner-background.jpg
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-12-10 15:23:102024-12-10 15:36:01ASM and RSNA Integrate GetFTR to Enhance Access from Article References
https://www.getfulltextresearch.com/wp-content/uploads/2024/12/R2R.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-12-19 16:41:152024-12-19 16:49:33Going to Researcher to Reader? Don’t forget to sign up for our workshop!
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/new-partner-background.jpg
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-12-10 15:23:102024-12-10 15:36:01ASM and RSNA Integrate GetFTR to Enhance Access from Article References https://www.getfulltextresearch.com/wp-content/uploads/2024/11/new-integration.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-11-28 15:46:382025-01-27 16:51:25IOPP integrates GetFTR retraction and errata service to further improve research integrity
https://www.getfulltextresearch.com/wp-content/uploads/2024/11/new-integration.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-11-28 15:46:382025-01-27 16:51:25IOPP integrates GetFTR retraction and errata service to further improve research integrity  https://www.getfulltextresearch.com/wp-content/uploads/2024/11/Counter-800-x-500-px.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-11-21 14:54:252024-11-21 14:57:58Syndicated usage reporting and GetFTR
https://www.getfulltextresearch.com/wp-content/uploads/2024/11/Counter-800-x-500-px.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-11-21 14:54:252024-11-21 14:57:58Syndicated usage reporting and GetFTR https://www.getfulltextresearch.com/wp-content/uploads/2024/11/increase-in-clicks-800-x-500-px.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-11-04 16:13:272024-11-04 16:13:27More Researchers Benefit from GetFTR Links to Trusted Content
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/new-partner-background.jpg
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-10-24 11:50:192024-10-24 17:05:28SEG Partners with GetFTR to Enhance Research Discovery
https://www.getfulltextresearch.com/wp-content/uploads/2024/11/increase-in-clicks-800-x-500-px.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-11-04 16:13:272024-11-04 16:13:27More Researchers Benefit from GetFTR Links to Trusted Content
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/new-partner-background.jpg
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-10-24 11:50:192024-10-24 17:05:28SEG Partners with GetFTR to Enhance Research Discovery https://www.getfulltextresearch.com/wp-content/uploads/2024/10/measuring-usage-scaled-e1729618494338.jpg
533
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-10-22 18:44:192024-10-22 18:46:36Measuring Usage via GetFTR
https://www.getfulltextresearch.com/wp-content/uploads/2024/10/measuring-usage-scaled-e1729618494338.jpg
533
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-10-22 18:44:192024-10-22 18:46:36Measuring Usage via GetFTR https://www.getfulltextresearch.com/wp-content/uploads/2024/09/GetFTR-Case-studies-2.png
1200
1200
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-09-30 16:13:362026-06-16 16:41:31APA PsycInfo A&I Integration Experience
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/new-partner-background.jpg
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-09-25 17:20:132024-09-25 17:21:39IEEE: latest publisher to join GetFTR
https://www.getfulltextresearch.com/wp-content/uploads/2024/09/GetFTR-Case-studies-2.png
1200
1200
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-09-30 16:13:362026-06-16 16:41:31APA PsycInfo A&I Integration Experience
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/new-partner-background.jpg
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-09-25 17:20:132024-09-25 17:21:39IEEE: latest publisher to join GetFTR https://www.getfulltextresearch.com/wp-content/uploads/2024/08/Product-update.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-08-04 09:59:372024-08-04 09:59:37GetFTR Browser Extension Update
https://www.getfulltextresearch.com/wp-content/uploads/2024/08/Product-update.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-08-04 09:59:372024-08-04 09:59:37GetFTR Browser Extension Update https://www.getfulltextresearch.com/wp-content/uploads/2024/08/Atypon800-x-500-px.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-08-03 14:49:342024-08-03 14:59:59Interview with Olly Rickard, Atypon
https://www.getfulltextresearch.com/wp-content/uploads/2024/08/Atypon800-x-500-px.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-08-03 14:49:342024-08-03 14:59:59Interview with Olly Rickard, Atypon https://www.getfulltextresearch.com/wp-content/uploads/2024/06/Coveri-1536x1024-1-e1722434239514.png
533
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-06-28 14:13:562026-06-16 16:42:06How R Discovery achieved increased engagement with GetFTR
https://www.getfulltextresearch.com/wp-content/uploads/2024/06/Coveri-1536x1024-1-e1722434239514.png
533
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-06-28 14:13:562026-06-16 16:42:06How R Discovery achieved increased engagement with GetFTR https://www.getfulltextresearch.com/wp-content/uploads/2024/06/GetFTR-Case-studies-800-x-500-px.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-06-24 15:36:242024-06-28 13:58:05Case Study: Thieme’s Integration with GetFTR
https://www.getfulltextresearch.com/wp-content/uploads/2024/06/GetFTR-Case-studies-800-x-500-px.png
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-06-24 15:36:242024-06-28 13:58:05Case Study: Thieme’s Integration with GetFTR https://www.getfulltextresearch.com/wp-content/uploads/2024/06/Press-Release-tile.png
1200
1200
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-06-13 10:44:462024-07-31 11:38:42GetFTR Extends Retraction and Errata Service to All Partners
https://www.getfulltextresearch.com/wp-content/uploads/2023/05/samantha-borges-EeS69TTPQ18-unsplash-scaled.jpg
1707
2560
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-06-04 10:54:302024-06-04 12:38:01GetFTR Integrator Webinar: 11th June 2024
https://www.getfulltextresearch.com/wp-content/uploads/2024/06/Press-Release-tile.png
1200
1200
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-06-13 10:44:462024-07-31 11:38:42GetFTR Extends Retraction and Errata Service to All Partners
https://www.getfulltextresearch.com/wp-content/uploads/2023/05/samantha-borges-EeS69TTPQ18-unsplash-scaled.jpg
1707
2560
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-06-04 10:54:302024-06-04 12:38:01GetFTR Integrator Webinar: 11th June 2024 https://www.getfulltextresearch.com/wp-content/uploads/2024/05/Crossref-2.png
1200
1200
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-05-05 16:13:012024-07-31 14:39:53Press Release: GetFTR collaborates with Crossref to strengthen research integrity
https://www.getfulltextresearch.com/wp-content/uploads/2023/05/samantha-borges-EeS69TTPQ18-unsplash-scaled.jpg
1707
2560
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-04-29 17:58:542024-04-29 18:00:15GetFTR Webinar: Recording and Slides available
https://www.getfulltextresearch.com/wp-content/uploads/2024/05/Crossref-2.png
1200
1200
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-05-05 16:13:012024-07-31 14:39:53Press Release: GetFTR collaborates with Crossref to strengthen research integrity
https://www.getfulltextresearch.com/wp-content/uploads/2023/05/samantha-borges-EeS69TTPQ18-unsplash-scaled.jpg
1707
2560
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-04-29 17:58:542024-04-29 18:00:15GetFTR Webinar: Recording and Slides available https://www.getfulltextresearch.com/wp-content/uploads/2024/04/DSC_3348-e1712232896900.jpg
533
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-04-04 13:26:032024-04-04 14:21:29Tracy Gardner joins GetFTR as Head of Marketing
https://www.getfulltextresearch.com/wp-content/uploads/2024/04/DSC_3348-e1712232896900.jpg
533
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-04-04 13:26:032024-04-04 14:21:29Tracy Gardner joins GetFTR as Head of Marketing https://www.getfulltextresearch.com/wp-content/uploads/2024/03/anniversary-scaled-e1711475287174.jpg
1709
2560
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-03-27 09:35:322024-03-27 12:16:09Happy 4th Anniversary! How GetFTR is evolving to meet the needs of the research community.
https://www.getfulltextresearch.com/wp-content/uploads/2024/03/anniversary-scaled-e1711475287174.jpg
1709
2560
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-03-27 09:35:322024-03-27 12:16:09Happy 4th Anniversary! How GetFTR is evolving to meet the needs of the research community. https://www.getfulltextresearch.com/wp-content/uploads/2024/03/man-giving-business-presentation-using-high-technology-digital-pen-scaled-e1711361459858.jpg
533
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-03-25 12:15:562024-03-25 12:30:27GetFTR Reports 350% increase in entitlement checks since launch of Browser Extension
https://www.getfulltextresearch.com/wp-content/uploads/2023/05/samantha-borges-EeS69TTPQ18-unsplash-scaled.jpg
1707
2560
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-03-13 14:24:162024-03-13 14:33:01Free Webinar: General Update and Information for Librarians
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/new-partner-background.jpg
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-02-29 13:15:062024-03-13 14:26:09Thieme go live and IOPP integrates GetFTR indicators with article references
https://www.getfulltextresearch.com/wp-content/uploads/2024/03/man-giving-business-presentation-using-high-technology-digital-pen-scaled-e1711361459858.jpg
533
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-03-25 12:15:562024-03-25 12:30:27GetFTR Reports 350% increase in entitlement checks since launch of Browser Extension
https://www.getfulltextresearch.com/wp-content/uploads/2023/05/samantha-borges-EeS69TTPQ18-unsplash-scaled.jpg
1707
2560
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-03-13 14:24:162024-03-13 14:33:01Free Webinar: General Update and Information for Librarians
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/new-partner-background.jpg
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-02-29 13:15:062024-03-13 14:26:09Thieme go live and IOPP integrates GetFTR indicators with article references https://www.getfulltextresearch.com/wp-content/uploads/2024/02/update-software-digital-eletronics-internet-concept-e1707743434453.jpg
512
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-02-12 13:13:232024-02-12 13:58:35GetFTR Plans for Retraction & Errata
https://www.getfulltextresearch.com/wp-content/uploads/2024/02/update-software-digital-eletronics-internet-concept-e1707743434453.jpg
512
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-02-12 13:13:232024-02-12 13:58:35GetFTR Plans for Retraction & Errata https://www.getfulltextresearch.com/wp-content/uploads/2024/02/business-people-shaking-hands-meeting-room-e1707150921800.jpg
468
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-02-05 16:39:522024-02-06 14:10:30Meet us at NISO Plus, R2R, ER&L and UKSG
https://www.getfulltextresearch.com/wp-content/uploads/2024/02/business-people-shaking-hands-meeting-room-e1707150921800.jpg
468
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2024-02-05 16:39:522024-02-06 14:10:30Meet us at NISO Plus, R2R, ER&L and UKSG https://www.getfulltextresearch.com/wp-content/uploads/2023/12/reading-article.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2023-12-13 12:08:182023-12-13 12:08:44Taylor & Francis Online Streamlines Researcher Access to Cited Articles Through GetFTR Integration
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/new-partner-background.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2023-12-08 11:17:022024-02-06 10:30:32ASM International, AACR and SciSummary latest to join GetFTR
https://www.getfulltextresearch.com/wp-content/uploads/2023/12/reading-article.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2023-12-13 12:08:182023-12-13 12:08:44Taylor & Francis Online Streamlines Researcher Access to Cited Articles Through GetFTR Integration
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/new-partner-background.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2023-12-08 11:17:022024-02-06 10:30:32ASM International, AACR and SciSummary latest to join GetFTR https://www.getfulltextresearch.com/wp-content/uploads/2023/11/8-reasons-checklist.jpg
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2023-11-23 18:27:232024-03-06 17:05:598 Reasons Researchers should use the GetFTR Browser Extension
https://www.getfulltextresearch.com/wp-content/uploads/2023/11/8-reasons-checklist.jpg
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2023-11-23 18:27:232024-03-06 17:05:598 Reasons Researchers should use the GetFTR Browser Extension https://www.getfulltextresearch.com/wp-content/uploads/2023/11/1700554566212.jpeg
1200
1200
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2023-11-20 14:50:272023-11-22 21:23:28American Chemical Society (ACS) Enhances Researcher Experience with Integration of GetFTR into Article References
https://www.getfulltextresearch.com/wp-content/uploads/2023/11/1700554566212.jpeg
1200
1200
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2023-11-20 14:50:272023-11-22 21:23:28American Chemical Society (ACS) Enhances Researcher Experience with Integration of GetFTR into Article References https://www.getfulltextresearch.com/wp-content/uploads/2023/06/growtika-dUMEnARXgJU-unsplash-2.jpg
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2023-10-31 12:46:022024-03-06 16:52:15GetFTR now works with Google Scholar, PubMed, Web of Science and more
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/new-partner-background.jpg
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2023-10-10 09:48:112023-10-10 10:35:13CABI, Edward Elgar & Royal College of Surgeons of England take advantage of GetFTR’s “free tier” initiative.
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/new-partner-background.jpg
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2023-07-06 09:27:502023-07-06 12:16:11Sage becomes latest publisher to join GetFTR
https://www.getfulltextresearch.com/wp-content/uploads/2023/06/growtika-dUMEnARXgJU-unsplash-2.jpg
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2023-06-15 10:56:332023-06-15 12:03:28Streamlined access to scholarly content with the GetFTR browser extension
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/new-partner-background.jpg
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2023-06-12 11:41:112023-06-14 11:55:08Oxford University Press and Geological Society of London go live with GetFTR
https://www.getfulltextresearch.com/wp-content/uploads/2023/06/growtika-dUMEnARXgJU-unsplash-2.jpg
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2023-10-31 12:46:022024-03-06 16:52:15GetFTR now works with Google Scholar, PubMed, Web of Science and more
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/new-partner-background.jpg
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2023-10-10 09:48:112023-10-10 10:35:13CABI, Edward Elgar & Royal College of Surgeons of England take advantage of GetFTR’s “free tier” initiative.
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/new-partner-background.jpg
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2023-07-06 09:27:502023-07-06 12:16:11Sage becomes latest publisher to join GetFTR
https://www.getfulltextresearch.com/wp-content/uploads/2023/06/growtika-dUMEnARXgJU-unsplash-2.jpg
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2023-06-15 10:56:332023-06-15 12:03:28Streamlined access to scholarly content with the GetFTR browser extension
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/new-partner-background.jpg
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2023-06-12 11:41:112023-06-14 11:55:08Oxford University Press and Geological Society of London go live with GetFTR https://www.getfulltextresearch.com/wp-content/uploads/2023/05/researchgate.jpg
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2023-05-18 12:11:542023-05-24 09:55:07ResearchGate integrates with GetFTR
https://www.getfulltextresearch.com/wp-content/uploads/2023/05/researchgate.jpg
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2023-05-18 12:11:542023-05-24 09:55:07ResearchGate integrates with GetFTR https://www.getfulltextresearch.com/wp-content/uploads/2023/04/headphones.jpg
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2023-04-27 12:01:252023-05-24 10:06:59GetFTR Webinar: Update and new use cases
https://www.getfulltextresearch.com/wp-content/uploads/2023/04/headphones.jpg
500
800
Tracy Gardner
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Tracy Gardner2023-04-27 12:01:252023-05-24 10:06:59GetFTR Webinar: Update and new use cases https://www.getfulltextresearch.com/wp-content/uploads/2023/03/browser.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2023-03-20 23:45:252024-03-06 16:49:06New service: GetFTR Browser Extension
https://www.getfulltextresearch.com/wp-content/uploads/2023/03/browser.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2023-03-20 23:45:252024-03-06 16:49:06New service: GetFTR Browser Extension https://www.getfulltextresearch.com/wp-content/uploads/2023/01/5-minutes.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2023-01-25 12:16:222023-02-10 16:57:07Understand GetFTR in just 5 minutes
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/new-partner-background.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2023-01-20 15:19:512023-02-10 17:42:51GetFTR welcomes American Meteorological Society and KGL PubFactory as new partners for 2023
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/5-minutes.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2023-01-25 12:16:222023-02-10 16:57:07Understand GetFTR in just 5 minutes
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/new-partner-background.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2023-01-20 15:19:512023-02-10 17:42:51GetFTR welcomes American Meteorological Society and KGL PubFactory as new partners for 2023 https://www.getfulltextresearch.com/wp-content/uploads/2023/02/calendar-desk-2022.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2023-01-12 16:36:512023-04-17 17:28:38GetFTR 2022 End of Year Roundup
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/new-partner-background.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2022-12-15 17:40:062023-02-10 17:44:09American Diabetes Association and American Physiological Society join GetFTR as publishing partners
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/new-partner-background.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2022-10-05 14:29:352023-02-10 17:44:41GetFTR welcomes two new publishers to a new program that waives costs for smaller organisations
https://www.getfulltextresearch.com/wp-content/uploads/2023/02/calendar-desk-2022.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2023-01-12 16:36:512023-04-17 17:28:38GetFTR 2022 End of Year Roundup
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/new-partner-background.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2022-12-15 17:40:062023-02-10 17:44:09American Diabetes Association and American Physiological Society join GetFTR as publishing partners
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/new-partner-background.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2022-10-05 14:29:352023-02-10 17:44:41GetFTR welcomes two new publishers to a new program that waives costs for smaller organisations https://www.getfulltextresearch.com/wp-content/uploads/2023/02/whats-new.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2022-09-27 14:42:252023-02-10 17:30:33GetFTR: What’s New and What’s Coming Up
https://www.getfulltextresearch.com/wp-content/uploads/2023/02/whats-new.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2022-09-27 14:42:252023-02-10 17:30:33GetFTR: What’s New and What’s Coming Up https://www.getfulltextresearch.com/wp-content/uploads/2023/03/research.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2022-05-26 18:57:132023-03-22 23:33:08GetFTR user research
https://www.getfulltextresearch.com/wp-content/uploads/2023/03/research.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2022-05-26 18:57:132023-03-22 23:33:08GetFTR user research https://www.getfulltextresearch.com/wp-content/uploads/2023/03/use-cases.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2022-05-12 19:15:032023-03-22 23:33:24Exploring new use cases
https://www.getfulltextresearch.com/wp-content/uploads/2023/03/use-cases.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2022-05-12 19:15:032023-03-22 23:33:24Exploring new use cases https://www.getfulltextresearch.com/wp-content/uploads/2022/03/journey.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2022-03-31 19:35:242023-03-22 23:33:39GetFTR’s journey so far
https://www.getfulltextresearch.com/wp-content/uploads/2022/03/journey.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2022-03-31 19:35:242023-03-22 23:33:39GetFTR’s journey so far https://www.getfulltextresearch.com/wp-content/uploads/2023/03/global-research.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2022-03-29 16:00:592023-04-17 17:35:18GetFTR now supports streamlined access to over 51% of global research output
https://www.getfulltextresearch.com/wp-content/uploads/2023/03/global-research.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2022-03-29 16:00:592023-04-17 17:35:18GetFTR now supports streamlined access to over 51% of global research output https://www.getfulltextresearch.com/wp-content/uploads/2023/03/aggregator-invite.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2022-02-02 23:13:312023-03-22 23:34:20GetFTR invites Aggregators to join
https://www.getfulltextresearch.com/wp-content/uploads/2023/03/aggregator-invite.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2022-02-02 23:13:312023-03-22 23:34:20GetFTR invites Aggregators to join https://www.getfulltextresearch.com/wp-content/uploads/2023/03/research-pilot.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2022-01-18 23:28:542023-03-22 23:32:01GetFTR supports ScienceDirect pilot to improve research discovery and access
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/new-partner-background.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2022-01-07 23:39:532023-03-22 23:41:21APA PsycInfo and R Discovery, CACTUS join GetFTR
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/new-partner-background.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2021-11-17 00:04:502023-03-23 00:05:40MyScienceWork partners with GetFTR: a new streamlined direction towards content
https://www.getfulltextresearch.com/wp-content/uploads/2023/03/research-pilot.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2022-01-18 23:28:542023-03-22 23:32:01GetFTR supports ScienceDirect pilot to improve research discovery and access
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/new-partner-background.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2022-01-07 23:39:532023-03-22 23:41:21APA PsycInfo and R Discovery, CACTUS join GetFTR
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/new-partner-background.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2021-11-17 00:04:502023-03-23 00:05:40MyScienceWork partners with GetFTR: a new streamlined direction towards content https://www.getfulltextresearch.com/wp-content/uploads/2023/03/break-barriers.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2021-11-09 00:13:442023-03-23 00:15:12Breaking down access barriers – Join GetFTR, SeamlessAccess and CONNECT
https://www.getfulltextresearch.com/wp-content/uploads/2023/03/break-barriers.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2021-11-09 00:13:442023-03-23 00:15:12Breaking down access barriers – Join GetFTR, SeamlessAccess and CONNECT https://www.getfulltextresearch.com/wp-content/uploads/2023/03/shape-future.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2021-09-16 00:22:382023-03-23 00:23:46Would you like to help shape the future of GetFTR?
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/new-partner-background.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2021-09-15 00:27:172023-03-23 00:28:20Silverchair partners American Medical Association and Rockefeller University Press join GetFTR
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/new-partner-background.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2021-07-29 00:31:582023-03-23 00:32:41Leading non-profit physical sciences publisher, AIP Publishing joins GetFTR
https://www.getfulltextresearch.com/wp-content/uploads/2023/03/shape-future.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2021-09-16 00:22:382023-03-23 00:23:46Would you like to help shape the future of GetFTR?
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/new-partner-background.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2021-09-15 00:27:172023-03-23 00:28:20Silverchair partners American Medical Association and Rockefeller University Press join GetFTR
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/new-partner-background.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2021-07-29 00:31:582023-03-23 00:32:41Leading non-profit physical sciences publisher, AIP Publishing joins GetFTR https://www.getfulltextresearch.com/wp-content/uploads/2023/03/seminar.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2021-05-24 00:37:512023-03-23 00:38:25Come and talk to us – Forthcoming Seminars
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/new-partner-background.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2021-05-18 00:41:232023-03-23 00:42:21Leading independent platform partner, Silverchair, joins GetFTR
https://www.getfulltextresearch.com/wp-content/uploads/2023/03/seminar.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2021-05-24 00:37:512023-03-23 00:38:25Come and talk to us – Forthcoming Seminars
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/new-partner-background.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2021-05-18 00:41:232023-03-23 00:42:21Leading independent platform partner, Silverchair, joins GetFTR https://www.getfulltextresearch.com/wp-content/uploads/2023/03/speed-data.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2021-05-07 13:43:572023-03-23 13:45:39GetFTR and SeamlessAccess – How can these services help speed the researcher journey?
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/new-partner-background.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2021-04-19 13:53:302023-04-17 17:40:54Future Science Group goes live with GetFTR
https://www.getfulltextresearch.com/wp-content/uploads/2023/03/speed-data.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2021-05-07 13:43:572023-03-23 13:45:39GetFTR and SeamlessAccess – How can these services help speed the researcher journey?
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/new-partner-background.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2021-04-19 13:53:302023-04-17 17:40:54Future Science Group goes live with GetFTR https://www.getfulltextresearch.com/wp-content/uploads/2023/03/2021-calendar.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2021-02-25 14:13:402023-04-17 17:43:07Moving firmly into 2021, what are we up to?
https://www.getfulltextresearch.com/wp-content/uploads/2023/03/2021-calendar.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2021-02-25 14:13:402023-04-17 17:43:07Moving firmly into 2021, what are we up to? https://www.getfulltextresearch.com/wp-content/uploads/2023/03/online-seminar.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2021-02-10 14:21:442023-03-23 14:22:26Online Seminar for Publisher and Integrators
https://www.getfulltextresearch.com/wp-content/uploads/2023/03/online-seminar.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2021-02-10 14:21:442023-03-23 14:22:26Online Seminar for Publisher and Integrators https://www.getfulltextresearch.com/wp-content/uploads/2023/03/youtube-sign.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2020-12-16 14:32:422023-03-23 14:35:24Missed our library seminar? The recording is now live
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/new-partner-background.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2020-12-10 14:40:112023-03-23 14:41:25Publisher the American Society of Civil Engineers and integrator Semantic Scholar are to join GetFTR
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/new-partner-background.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2020-12-03 14:51:432023-04-17 17:46:56CHORUS now using GetFTR to support open research compliance for publicly funded research
https://www.getfulltextresearch.com/wp-content/uploads/2023/03/youtube-sign.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2020-12-16 14:32:422023-03-23 14:35:24Missed our library seminar? The recording is now live
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/new-partner-background.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2020-12-10 14:40:112023-03-23 14:41:25Publisher the American Society of Civil Engineers and integrator Semantic Scholar are to join GetFTR
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/new-partner-background.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2020-12-03 14:51:432023-04-17 17:46:56CHORUS now using GetFTR to support open research compliance for publicly funded research https://www.getfulltextresearch.com/wp-content/uploads/2023/03/seminar2.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2020-12-02 15:00:112023-03-23 15:00:49Join us for a librarian seminar – 10th December
https://www.getfulltextresearch.com/wp-content/uploads/2023/03/seminar2.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2020-12-02 15:00:112023-03-23 15:00:49Join us for a librarian seminar – 10th December https://www.getfulltextresearch.com/wp-content/uploads/2023/03/expand-access.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2020-11-04 15:05:432023-04-17 17:48:35Preserving data privacy and expanding access options
https://www.getfulltextresearch.com/wp-content/uploads/2023/03/expand-access.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2020-11-04 15:05:432023-04-17 17:48:35Preserving data privacy and expanding access options https://www.getfulltextresearch.com/wp-content/uploads/2020/10/missed-seminar.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2020-10-31 15:14:302023-03-23 15:42:19Missed us at Charleston?
https://www.getfulltextresearch.com/wp-content/uploads/2020/10/missed-seminar.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2020-10-31 15:14:302023-03-23 15:42:19Missed us at Charleston? https://www.getfulltextresearch.com/wp-content/uploads/2023/03/launch.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2020-10-21 15:54:282023-03-23 16:04:19On the road to launch – A few updates from the GetFTR pilot
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/new-partner-background.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2020-09-02 16:08:112023-03-23 16:08:50Karger Publishers trials GetFTR
https://www.getfulltextresearch.com/wp-content/uploads/2023/03/launch.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2020-10-21 15:54:282023-03-23 16:04:19On the road to launch – A few updates from the GetFTR pilot
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/new-partner-background.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2020-09-02 16:08:112023-03-23 16:08:50Karger Publishers trials GetFTR https://www.getfulltextresearch.com/wp-content/uploads/2023/03/behind-scenes.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2020-06-08 19:09:172023-04-17 17:50:47Behind the scenes with Researcher: What does integration look like for GetFTR’s latest adopter?
https://www.getfulltextresearch.com/wp-content/uploads/2023/03/behind-scenes.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2020-06-08 19:09:172023-04-17 17:50:47Behind the scenes with Researcher: What does integration look like for GetFTR’s latest adopter? https://www.getfulltextresearch.com/wp-content/uploads/2023/03/launch-card.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2020-04-21 19:18:512023-04-17 17:52:23GetFTR pilot is now live
https://www.getfulltextresearch.com/wp-content/uploads/2023/03/launch-card.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2020-04-21 19:18:512023-04-17 17:52:23GetFTR pilot is now live https://www.getfulltextresearch.com/wp-content/uploads/2023/03/checklist.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2020-02-11 23:19:122023-03-23 23:19:46A good start to 2020 but there’s a lot to do
https://www.getfulltextresearch.com/wp-content/uploads/2023/03/checklist.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2020-02-11 23:19:122023-03-23 23:19:46A good start to 2020 but there’s a lot to do https://www.getfulltextresearch.com/wp-content/uploads/2023/03/networking-community.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2019-12-11 23:29:562025-10-24 09:26:15Updating the community
https://www.getfulltextresearch.com/wp-content/uploads/2023/03/networking-community.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2019-12-11 23:29:562025-10-24 09:26:15Updating the community https://www.getfulltextresearch.com/wp-content/uploads/2023/03/fast-access-to-data.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2019-12-03 23:38:502023-03-23 23:39:26New service from publishers to streamline access to research
https://www.getfulltextresearch.com/wp-content/uploads/2023/03/fast-access-to-data.jpg
500
800
Simon Hicks
https://www.getfulltextresearch.com/wp-content/uploads/2023/01/getftr-colour-B.svg
Simon Hicks2019-12-03 23:38:502023-03-23 23:39:26New service from publishers to streamline access to research
